
Introduction
In my current project, we have to deal with 30.000.000 records for the initialization run and about 10.000.000 records each day. The big problem is we have no SAP HANA system for BW. So, we have to build a perfect data model to load the data and push it through the BW to deliver it to another DWH system. First I want to describe how our first steps worked and then which parameter we changed to make it more efficient. I will also describe where we had our problems and how we have solved them. So let's go.
We receive the data from a Bank Analyzer (BA) system and have to put it into a DataStore-Object (DSO) to get a delta logic. So, we designed a Semantic Partitioning Object (SPO) with the criteria 0FISCPER. We don't want to build it on 0CALMONTH because this can nobody administrate. In the routine, we have to do some logic for master data because we get a master data record not every day, so we decided to build a DSO which it build like a time-dependent InfoObject. The reason why we would use a time-dependent InfoObject is, because we also have 10.000.000 records and this is hard to execute the attribute changes for so many records.
So when we get a new record we set the valid-to date to 31.12.9999 and when we receive a new entry for the same record, we adjust the valid-to date to new start date minus 1. In case we have to make a build the records for the transaction data again, we have a clean history.
Our first load from the data source into the data acquisition layer for the 30.000.000 records last 3 hours. Plus activation of almost 2 hours. So that we have the data only in the first layer of our data model took us 5 hours + 1 hour to extract it from the source system.
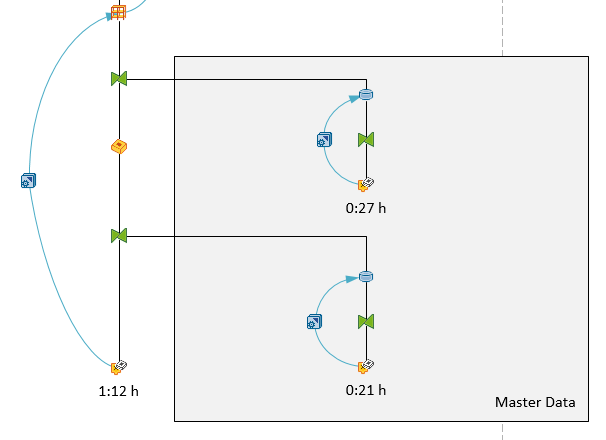
After we had the data in the data acquisition layer we want to load it into InfoCubes for reporting and add also some logic. We build a SPO again, but this time we separated it into 0FISCPER and accounting system (AS). So we have now instead of two cubes (2016 and 2017) now four cubes (2016 AS1, 2016 AS2, 2017 AS1, 2017 AS2). So next year we get two new cubes and so on.
Now we have only around 15.000.000 records for each accounting system. Just a note, the test data is only for 2016 so we have no data for 2017. The initial load of the data from the changelog of the DSO took us more than 16 hours.
Summary
Until a user can execute his report with the new data, he had to wait about 22 hours. So we have to analyze what our problems were:
- Consider the transformation from the data source to the DataStore-Object
- See if we could accelerate the activation process of the DSO
- Consider our InfoCube design to see where we lost so much time
Activities
So our big issue was that it took us round 7 minutes for one package of 50.000 entries into the InfoCube. So, we analyzed the data model which exists from a former project with the report SAP_INFOCUBE_DESIGNS. And it showed us that we have three terrible dimensions. After we fixed the design of the InfoCube we load the data again and it took us now 3 hours. This is an improvement of to 19% of the original time. So it is very important how your data model is designed. Especially when you have to deal with mass data.
Besides the data model we also add number range buffering for DIM IDs and SIDs. For more information have a consider SAP Note 857998. This also improve our activation time, but more about that later. So now we have to deal with the 3 hours of data loading from the data source to our DSO.
We looked into our start- and end-routines and adjust our ABAP code so now we were down from 3 hours to 42 minutes. This is now only 23% of the original time. These two big improvements saved us about 15 hours. So we are now down from 22 to 7 hours for the processing. Besides our data model and ABAP correction, we also increased our parallel processing. For this open the RSA1 and click on the administration tab and select under Current Settings >> DataStore Objects. You can also execute the report RSODSO_MAINTAIN_SETTINGS.
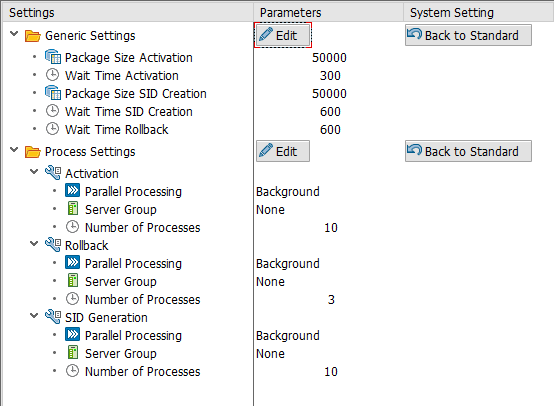
Select now your DSO and you can edit the parameter on the right side. For example, we choose the Package Size Activation with 50.000 and the Package Size SID Creation with 50.000. Besides these two sizes we also adjust the parallel processing of activation and SID generation to 10 processes. This maybe depends how many processes your system have.
And we also increased the parallel processing of the DTP to 7 from 3 processes.
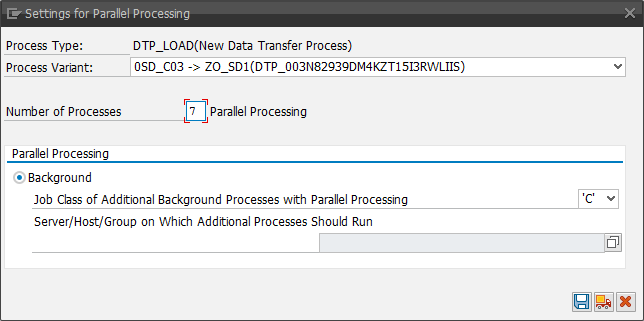
The next step was to improve the activation time. Our first try was 1 hour 54 Minutes. After we add the buffering of number ranges, we went down to 1 hour 25 Minutes. It is a benefit of 29 Minutes or round 26%.
So we have now a data loading time down from 23 hours to 6 hours 30 minutes. So we are now only need 28 % from the time of our first try. This is really impressive, because you have to keep in mind, that we have no HANA system.
These posts might also be interesting:
author.
I am Tobias, I write this blog since 2014, you can find me on twitter and youtube. If you want you can leave me a paypal coffee donation. You can also contact me directly if you want.



Write a comment